Реальность наносит ответный удар: почему хваленый ИИ набирает 0% в новом бенчмарке 🔨
Вот только что я эссе Джека Кларка о скорой сингулярности и порванном в клочья SWE-Bench, где фигурировали красивые цифры: топовые ИИ выбивают 93.9% на SWE-Bench, почти автономно закрывая реальные issue с GitHub. Казалось бы, пора удалять IDE и идти учиться на баристу.
Но вот ребята из Стэнфорда и Гарварда выкатили новый бенчмарк — ProgramBench. И он публично унизил все существующие frontier-модели.
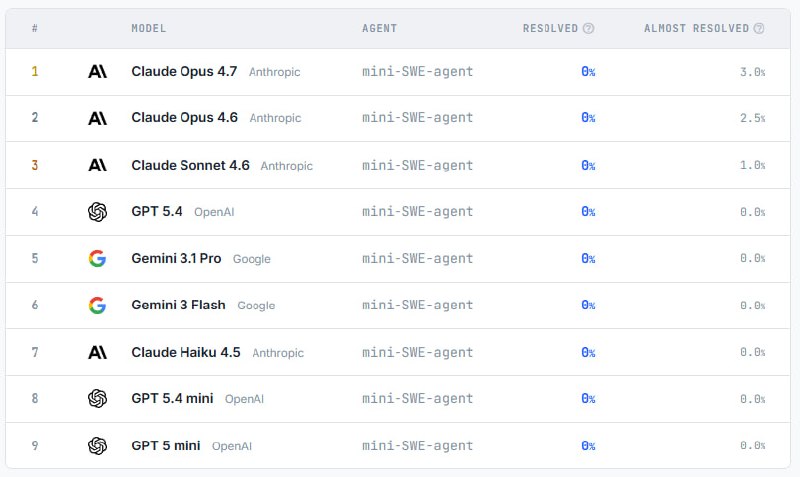
Спойлер: результат GPT-5.4, Claude Opus 4.7 и Gemini 3.1 Pro — ровно 0%.
В чем суть?
Агенту дают скомпилированный бинарник (от условного jq до монстров вроде FFmpeg или SQLite) и документацию.
Задача — с нуля написать кодовую базу, которая на 100% воспроизведет поведение оригинала.
Отдельный кек в том, как авторам пришлось огораживать песочницу. Изначально, когда доступ в сеть был открыт, нейронки вместо "написания кода" просто парсили --help, находили нужный репозиторий на GitHub и делали git clone. Когда сеть отрезали, агенты пытались качать исходники через пакетные менеджеры или тупо писали bash-обёртки вокруг исходного бинарника.
Чтобы закрыть эту клоунаду, контейнеры полностью изолировали, а бинарникам выставили права 111 (только исполнение). Никакого чтения. Чистый black-box реверс-инжиниринг: кормишь инпуты, смотришь аутпуты, пишешь реализацию на любом Тьюринг-полном языке.
И тут выяснилась потрясающая вещь. Одно дело — скормить нейронке готовый репозиторий с выстроенной архитектурой, где ей нужно лишь написать патч из 50 строк. И совершенно другое — заставить её спроектировать систему.
Как только ИИ лишается "костылей" в виде готовых абстракций, придуманных мясными инженерами, он сыпется. Выясняется, что модели не умеют в системный дизайн, декомпозицию и построение интерфейсов. Они физически не могут удержать в "голове" архитектуру с нуля, если им не дать жесткие рамки. И это при том, что модели сжигали до $5000 за один прогон, не упираясь в лимиты контекста.
Короче, мясные мешки еще повоюют. 💪
Комментарии
0Комментариев пока нет.
Войдите, чтобы участвовать в обсуждении.