Эффект "свой-чужой" в IT-найме: почему писать резюме руками статистически невыгодно 🤖
Эффект "свой-чужой" в IT-найме: почему писать резюме руками статистически невыгодно 🤖
Свежее исследование математически доказало системный баг в современных пайплайнах найма.
На рынке сложилась ситуация, когда кандидаты генерируют резюме нейросетками, а компании используют те же LLM для первичного скрининга. Исследователи измерили, что происходит, когда эти два процесса сталкиваются.
Они взяли 2245 реальных человеческих резюме, сгенерировали на их основе копии через разные LLM (хард-скиллы и опыт оставались 1:1, менялись только формулировки и подача) и скормили их LLM-оценщикам.
И вот что вышло:
1️⃣ Self-preference bias (Предпочтение себя). Модели обладают встроенным механизмом самораспознавания и систематически выбирают текст, написанный ими же. Уровень предвзятости против текстов, написанных живым человеком, составляет от 67% до 82% для GPT-4o, DeepSeek-V3 и LLaMA-3.3-70B.
2️⃣ Конверсия в шорт-лист. Кандидат, чье резюме отполировано той же LLM, которую использует компания для скрининга, имеет на 23–60% больше шансов получить приглашение на интервью. При абсолютно идентичном бэкграунде.
3️⃣ Слепота к качеству. В слепых тестах живые разметчики часто признавали оригинальные человеческие резюме более понятными и логичными. Но LLM-скринеры всё равно выбирали сгенерированные версии, просто потому что узнавали собственные лингвистические паттерны.
Отдельная статистика есть по битвам между самими моделями, если кандидат и компания используют разные инструменты:
▫️ DeepSeek-V3 обладает самым высоким уровнем "нарциссизма": он выбирает свои тексты против текстов LLaMA-3.3-70B на 69% чаще, а против GPT-4o — на 28%.
▫️ GPT-4o, напротив, в парных сравнениях внезапно отдавал предпочтение резюме, написанным DeepSeek, дисконтируя собственные генерации.
В общем, отправляя полностью "крафтовое", написанное руками резюме, вы технически отдаете до 60% преимущества в скрининге тем, кто прогнал текст через промпт. Навык попасть стилистикой резюме в LLM-пайплайн конкретной корпорации теперь влияет на конверсию до собеседования сильнее, чем реальный коммерческий опыт.
Как же все сломано ☹️ DeepSeek V4 Preview оказалась лучшим ИИ в математике и коде среди open source моделей
DeepSeek выпустила V4 Preview с открытыми весами.
DeepSeek-V4-Pro : 1,6 Тб общего объема / 49 Б активных параметров. Производительность, сопоставимая с лучшими в мире моделями с закрытым исходным кодом.
Тестируем здесь
🫥 UNSERO: Цифровой Горизонт 🤖 DeepSeek представила новую модель, которая «догоняет» лидеров рынка ИИ

DeepSeek объявила о предварительном просмотре новой архитектуры своих моделей искусственного интеллекта. По словам компании, благодаря улучшениям в архитектуре, новые модели стали значительно более эффективными и производительными по сравнению с предыдущей версией DeepSeek V3.2. Ключевое достижение — эти модели почти «сократили разрыв» с текущими лидирующими моделями, как открытыми, так и закрытыми, в стандартных тестах на логическое мышление и рассуждение (reasoning benchmarks).
#DeepSeek #ИИ_Архитектура #ReasoningBenchmarks Запускаем Claude Code без ключа от Anthropic 🏴☠️
Запускаем Claude Code без ключа от Anthropic 🏴☠️
Недавно появился очень любопытный проект free-claude-code. По факту это прокси-сервер на FastAPI, который подменяет собой эндпоинты Anthropic. Вы скармливаете ему запросы от оригинального Claude Code, а он роутит их куда вам выгодно: в бесплатный тир NVIDIA NIM, в OpenRouter, напрямую в DeepSeek или вообще в локальный LM Studio / llama.cpp.
Что тут интересного (кроме очевидной халявы):
1️⃣ Heuristic Tool Parser
Дешевые или локально запущенные квантованные модели часто тупят с вызовом тулзов в строгом формате. Автор написал собственную стейт-машину (providers/common/heuristic_tool_parser.py), которая парсит сырой текстовый выхлоп модели и прямо в стриме заворачивает его в легитимный Anthropic tool_use блок. Идеальный костыль для глупых моделей, чтобы заставить их работать с инструментами Claude.
2️⃣ Перехват служебного трафика
В api/optimization_handlers.py реализован локальный перехват "мусорных" реквестов. Claude Code под капотом постоянно шлет запросы на чек квоты, генерацию тайтлов для истории, автокомплит путей к файлам и саджесты. Прокси отбивает их сам захардкоженными ответами, вообще не дергая внешнюю LLM. Экономит время, деньги и лимиты.
3️⃣ Трансляция рассуждений на лету
ThinkTagParser в реальном времени выкусывает теги <think> (привет, DeepSeek-R1) или извлекает reasoning_content из ответа провайдера, мапя их в официальные thinking блоки Anthropic. Для клиента это выглядит так, будто отвечает нативный Claude.
Как дикий бонус: к прокси прикручен хендлер для Telegram и Discord. Можно натравить бота на локальную папку с проектом, кидать ему войсы (транскрибируются через локальный Whisper), а агент будет писать код у вас на компе. Идеально, если хочется пофиксить прод, пока едешь в такси (пожалуйста, не надо так делать).
Срочно пробовать! Отпишитесь потом, можно ли работает ли очередная спасительная халява ☕️ DeepSeek выпустил V4 — предварительную версию модели, которая напрямую бросает вызов GPT-5
DeepSeek выпустил V4 — предварительную версию модели, которая напрямую бросает вызов GPT-5.4 и Claude Opus 4.5. Но самое интересное не в бенчмарках (хотя они тоже впечатляют).
Вот что реально важно:
🔹 Работает на чипах Huawei. Да, не Nvidia. DeepSeek полностью адаптировал V4 под китайские процессоры, что говорит о двух вещах: технологическая независимость Китая в ИИ уже не мем, а реальность; и Nvidia теперь есть о чём беспокоиться не только со стороны AMD.
🔹 Контекстное окно — 1 миллион токенов. Для сравнения: это целая база кода среднего стартапа или 3-4 длинных юридических контракта, которые модель может проанализировать за один запрос. Claude Opus с таким же окном стоит в 10 раз дороже.
🔹 Открытый исходный код. Пока западные лаборатории продают API-доступ по премиум-ценам, DeepSeek раздаёт модель бесплатно. Результат? Китайские чипмейкеры взлетели на 15-20% за день после анонса.
🔹 Два режима: Pro и Flash. Один для сложных задач (код, аналитика, научные статьи), другой для скорости. При этом оба — дешевле аналогов от западных конкурентов.
Венчурный угол:
Стоимость обучения ИИ-моделей только что упала ещё ниже. Если раньше считалось, что за frontier-моделями будущее только у гигантов с миллиардными бюджетами, DeepSeek доказывает обратное — умные архитектурные решения (Hybrid Attention, оптимизация под конкретные чипы) могут компенсировать меньшие вычислительные ресурсы.
Вопрос дня: если Китай сможет производить конкурентоспособные ИИ-модели на собственных чипах и по цене в 5-10 раз ниже западных — как изменится глобальная конкуренция в enterprise-сегменте?
Я в Telegram: t.me/digitalvc
Я в Макс: bit.ly/4unwp5X
Я в VK: vk.ru/dreidman 🔴 DeepSeek V4 — китайцы снова всё сломали

🔴 DeepSeek V4 — китайцы снова всё сломали.
Две модели. Бесплатно. Open source.
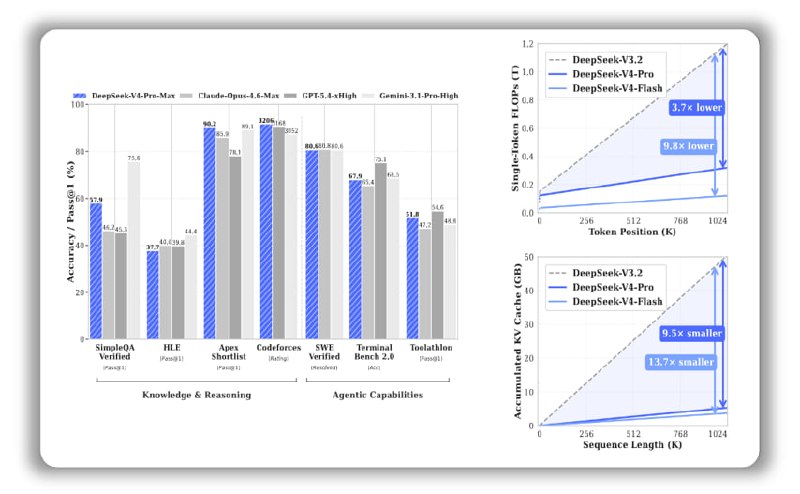
V4-Pro — 1,6 трлн параметров, топ по коду и математике.
V4-Flash — 284 млрд (активны 13 млрд), быстрее и дешевле.
Против GPT-5.4, Claude Opus 4.6, Gemini 3.1:
— Codeforces: 3206 — выше GPT-5.4 (3168) и Gemini (3052)
— LiveCodeBench: 93.5 — лучший из всех
— HMMT 2026: 95.2 — топ по сложной математике
— IMOAnswerBench: 89.8 — выше всех конкурентов
Эффективность vs V3.2:
V4-Pro потребляет в 4 раза меньше FLOPs, V4-Flash — в 10 раз. 50 ГБ KV-кэша у V3.2 → 5 ГБ у V4-Flash. Больше запросов, меньше железа.
Интеграция с Claude Code и Codex из коробки.
MUSIN PRO | DeepSeek V4
#DeepSeek #AI #нейросети #OpenSource #LLM