Работа с памятью и историей диалога в LLM 🧠

Работа с памятью и историей диалога в LLM 🧠
Выкатывается очередной чат-бот техподдержки, юзер распинается о своей проблеме, а на третьем сообщении нейронка спрашивает: «Как вас зовут и чем могу помочь?».
Причина банальна: LLM по своей природе stateless. «Память» модели — это просто архитектурный костыль, и обычно проблему решают «в лоб»: берут LangChain, собирают все предыдущие сообщения и кидают в промпт.
🗓 Сегодня в 18:00 по мск в «Точке Сборки» будем разбирать архитектуру памяти для LLM-ассистентов и методы адекватного управления контекстом.
Необходимая база для понимания материала:
🔵Базовый синтаксис Python (классы, словари, функции).
🔵Понимание работы HTTP API и базовой концепции LLM (что такое промпт и токен).
🔵 Поверхностное знакомство с абстракциями LangChain.
Доступ через бота: t.me/TScompiler_bot
Иногда нейронка выдаёт эпичные перлы
Иногда нейронка выдаёт эпичные перлы
Я частенько делаю обложки для статей, объединяя персонажей с разных постеров, промо, кадров и т. п. Но порой ИИ не так понимает запрос и создаёт настоящие шедевры. Поделюсь порцией таких фейлов с одной из последних генераций, когда я пытался объединить «Пацанов», «Вот это драма!», «Очень странные дела: Истории из 85», «Космос засыпает» Работа с памятью и историей диалога в LLM 🧠

Работа с памятью и историей диалога в LLM 🧠
Выкатывается очередной чат-бот техподдержки, юзер распинается о своей проблеме, а на третьем сообщении нейронка спрашивает: «Как вас зовут и чем могу помочь?».
Причина банальна: LLM по своей природе stateless. «Память» модели — это просто архитектурный костыль, и обычно проблему решают «в лоб»: берут LangChain, собирают все предыдущие сообщения и кидают в промпт.
🗓 14 апреля в 18:00 по мск в «Точке Сборки» будем разбирать архитектуру памяти для LLM-ассистентов и методы адекватного управления контекстом.
Необходимая база для понимания материала:
🔵Базовый синтаксис Python (классы, словари, функции).
🔵Понимание работы HTTP API и базовой концепции LLM (что такое промпт и токен).
🔵 Поверхностное знакомство с абстракциями LangChain.
Доступ через бота: t.me/TScompiler_bot
Хватит говорить нейросетям, что они Senior-разработчики 🛑
Хватит говорить нейросетям, что они Senior-разработчики 🛑
Наверняка вы все используете одно из базовых правил промпт-инжиниринга: начинайте запрос с фразы типа «Представь, что ты Senior Python Developer сд 100 годами опыта в Google». Да, я тоже так делаю.
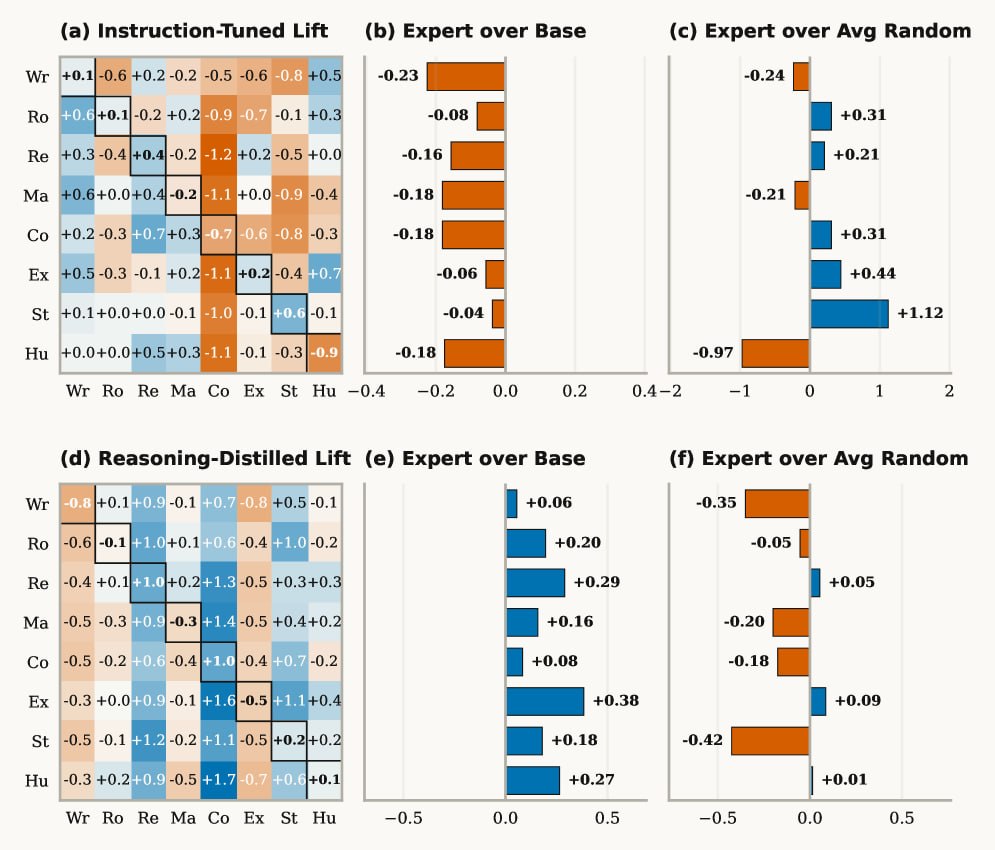
Так вот, выкатили свежее исследование от USC, которое доказывает, что такие фразы делают модель тупее в написании кода.
Почему так? 🧐
Сырые знания (факты, алгоритмы, логика) закладываются в модель на этапе pretraining. А вот умение отыгрывать роль, следовать формату и быть безопасной — это результат instruction-tuning (SFT/RLHF).
Когда вы пишете You are an expert..., вы переводите модель в режим жесткого следования инструкциям. Ее внутренние веса смещаются в сторону поддержания этой маски (alignment-задачи). Модель тратит «вычислительный ресурс» на то, чтобы звучать как эксперт, вместо того чтобы думать как эксперт. Происходит интерференция: instruction-following паттерны подавляют нейронные пути, отвечающие за извлечение чистых фактов из претрейна.
Цифры из пейпы: на бенчмарках вроде MMLU и задачах на кодинг/математику базовая модель с голым промптом стабильно обходит модель с навешанной персоной (68% против 71.6% accuracy). Нейронка буквально тупеет в логике, пытаясь генерировать уверенный в себе, красиво структурированный булшит. Особенно сильно этот эффект бьет по reasoning-моделям вроде DeepSeek-R1, ломая им цепочки рассуждений.
Значит ли это, что персоны вообще не нужны? Нет.
Исследование четко разделяет задачи:
1️⃣ Где персона вредит (Pretraining-dependent tasks):
Кодинг, математика, извлечение сырых фактов, логические загадки.
Как надо: Дайте голый контекст и четкую задачу. Никаких «ты эксперт».
2️⃣ Где персона работает (Alignment-dependent tasks):
Написание текстов, форматирование (собрать данные в JSON определенной структуры), тон общения и, как ни странно, safety (отказы писать эксплойты).
Как надо: Здесь Ты — строгий критик или Ты — технический писатель реально улучшит структуру ответа.
Для тех, кто хочет вкопаться глубже: исследователи даже собрали костыль PRISM — LoRA-адаптер с гейтом, который на лету включает персону для форматирования и вырубает её, когда дело доходит до хардкорного кодинга и фактов.
В общем, теперь знаем, что если вам нужен работающий код или решение сложной архитектурной задачи — перестаем уговаривать железяку, что она гений. Просто нормально пишем ТЗ. Что на самом деле делают люди на работе с нейросетями?
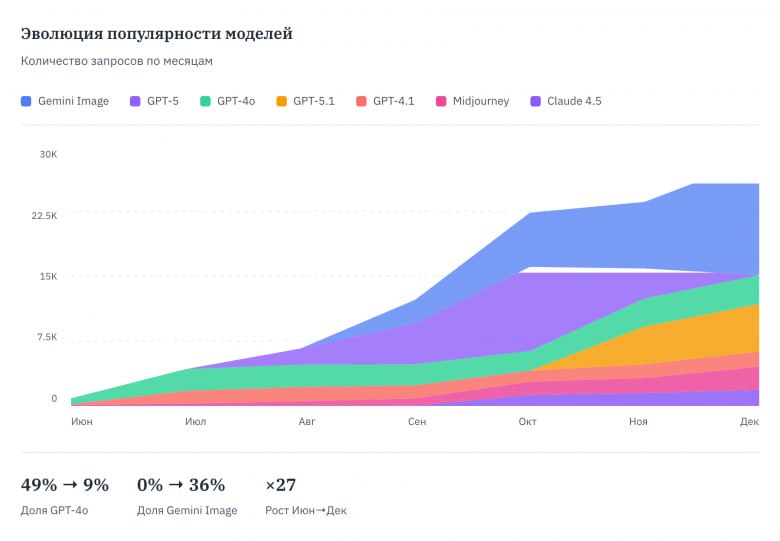
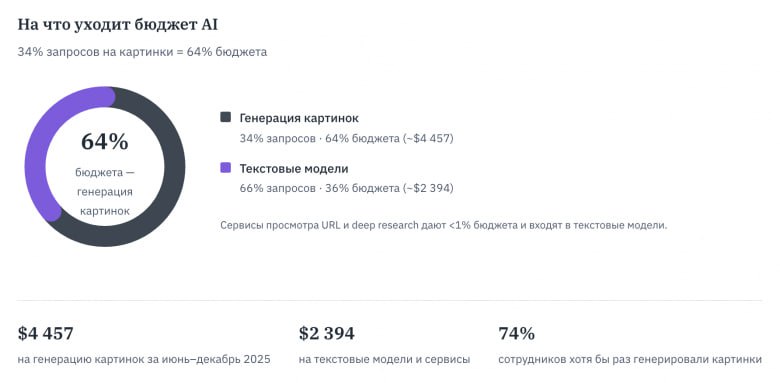
Сотрудникам небольшой компания (чуть более 500 человек) дали доступ ко всем популярным нейросетям, что есть на рынке, чтобы посмотреть, что произойдёт. Пристегните ремни, сейчас будет интересно.
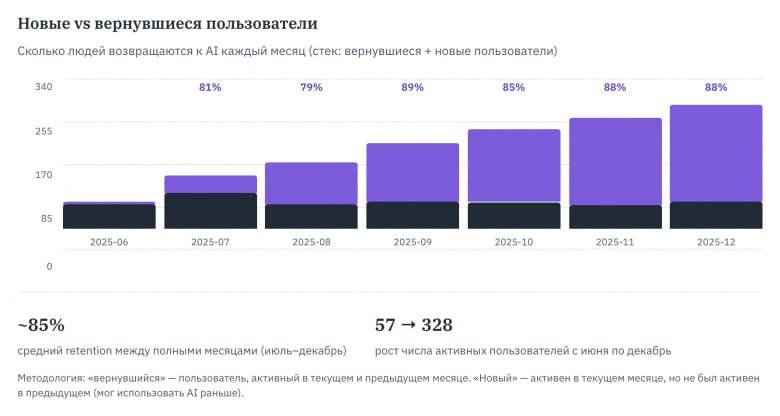
— 416 пользователей из 527 хоть раз потыкались
— 122346 запросов (в среднем 42 запроса на пользователя в месяц)
— 6851 доллар расходов (535 тысяч рублей, 184 руб/месяц на активного юзера)
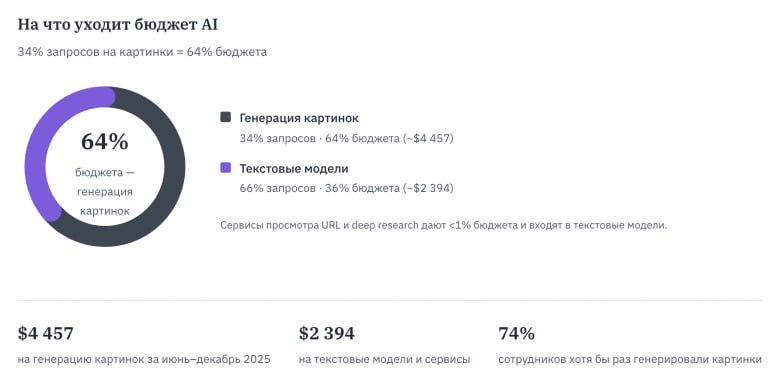
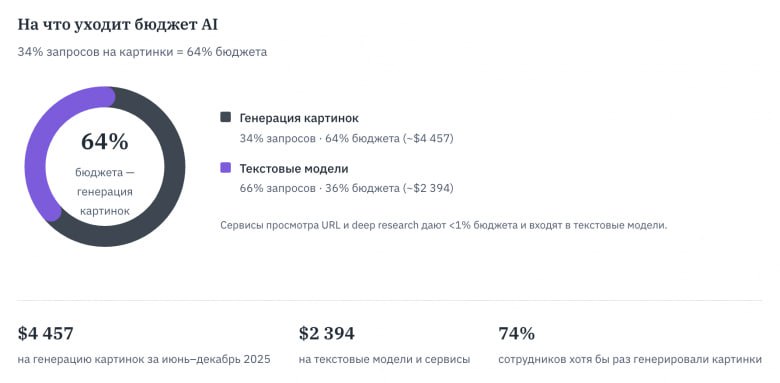
❗️ 64% бюджета ушло на генерацию картинок.
❗️ 20% пользователей генерируют 79,4% расходов
Иногда вы это знаете, иногда нет, но 50-60% ваших сотрудников уже используют нейросети в работе. Ежедневно. Вопрос не в том, внедрять ли. Вопрос в том, контролируете вы это или нет. 71% офисных работников используют AI без одобрения IT. 38% делятся конфиденциальными данными компании с публичными AI-сервисами.
P.S. Если решите повторить опыт, то выбирайте оплату за токены — выйдет дешевле.
TG | MAX | VK | ДЗЕН | #ИИ #AI #нейронка #интеллект #исследование Кибербезопасность вайбкод продуктов
Кибербезопасность вайбкод продуктов
Меня позвали в прямой эфир к Известиям, поговорить про кибер угрозы и использование ИИ применительно к этой теме.
Вот вам кусочек из эфира, где я говорю про уязвимость продуктов написанных с помощью ИИ.
В целом, ничего нового, про это давно идёт разговор и кибербез как никогда в тренде. Кроме уязвимости вайбкод продуктов ещё есть такой занимательный факт, что киберпреступники тоже легко поднимают себе на том же mac mini свою модель, обучают ее на созданных вирусах и эта нейронка теперь клепает их с невероятной скоростью.
А ещё, оказывается, есть целая обученная модель в том числе для создания вирусов. Название давать не буду чтоб вы сами себе ПК не сломали случайно об нее. То есть это не локальная модель а вполне публичная большая языковая модель. Просто там кроме прочего обучали ещё и на вирусах.
Тема большая, одним постом ее не раскрыть, но смысл, думаю, уловили. К тому же я не эксперт по кибербезопасности. Пока что кайфаните от видоса) Доля ChatGPT стремительно сокращается
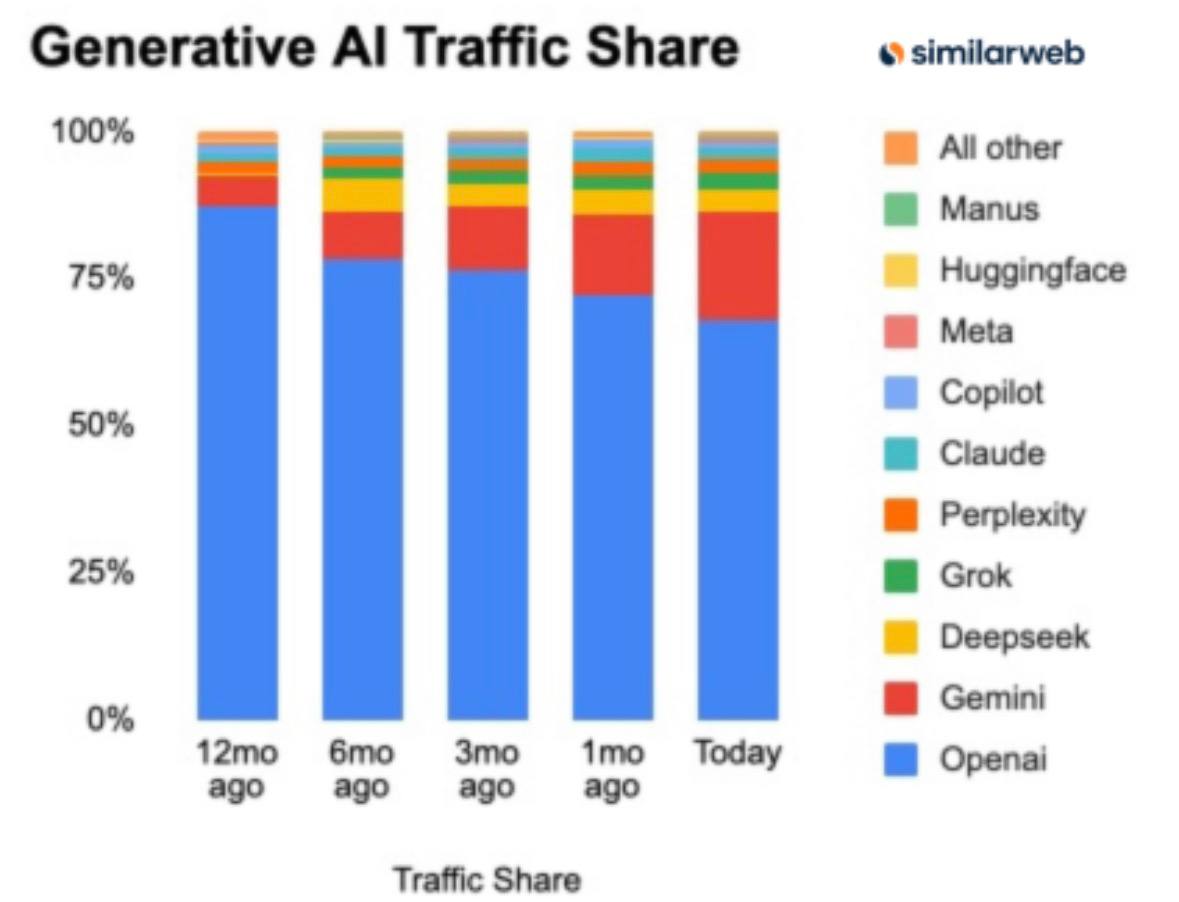
Аналитика от Similarweb по доле разных нейронок в веб-траффике. В начале года доля ChatGPT составляла 87,2%, теперь же только — 68,0%. Между тем, компания приблизилась к отметке 900 млн уникальных пользователей в неделю.
Главный конкурент Gemini за год вырос с 5,4% до 18,2%. Главное оружие Google — это собственная экосистема: AI выдача в поисковике, Ассистент Gemini по умолчанию в Android. 76% всего траффика приходится на домен google.com.
⚔️ Две разные стратегии:
ChatGPT — это осознанный выбор. Люди целенаправленно идут на сайт, потому что считают его лучшим инструментом, ну или работает сарафанное радио. Это армия преданных фанатов.
Google Gemini — это сила дистрибуции. Он просто оказывается у вас под рукой, встроенный во всё, чем вы и так пользуетесь. Это победа за счет тотального присутствия.
Кто возьмёт вверх? Классный продукт или сила дистрибуции?
TG | MAX | VK |ДЗЕН| #ИИ #AI #нейронка #gemini #google #тренды