Запускать локальные LLM на своём железе уже давно не удел избранных с кластерами из H100

Запускать локальные LLM на своём железе уже давно не удел избранных с кластерами из H100. Или все же удел? 😁
🗓 Уже сегодня в 18:00 по мск пройдет прямой эфир в «Точке Сборки». Будем разбирать установку и использование локальных моделей.
О чем пойдет речь:
▪️ Как выбрать подходящую модель под ваше железо, чтобы она не сожрала всю память системы и работала с адекватным TPS (tokens per second).
▪️ Поднятие модели в режиме чата для повседневных задач.
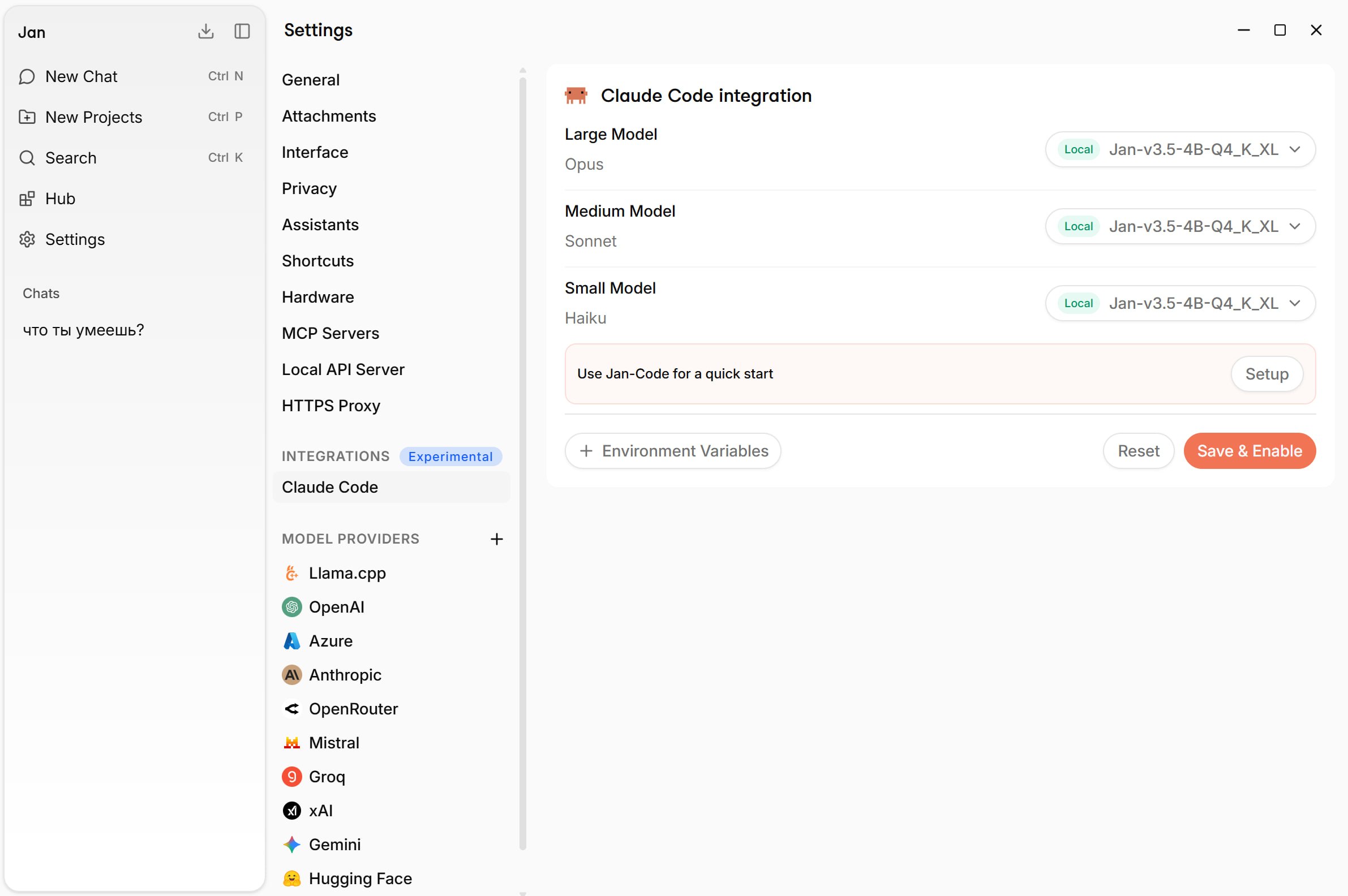
▪️ Подключение локальной LLM к агентной IDE (в качестве примера возьмем Kilo Code).
▪️ Маршрутизация запросов к локалке через LangChain.
▪️ Оно вообще надо?
Трансляция и запись будут доступны участникам «Точки Сборки». Оформление доступа происходит через бота: https://t.me/TScompiler_bot
Запускать локальные LLM на своём железе уже давно не удел избранных с кластерами из H100

Запускать локальные LLM на своём железе уже давно не удел избранных с кластерами из H100. Или все же удел? 😁
🗓 1 мая в 18:00 по мск пройдет прямой эфир в «Точке Сборки». Будем разбирать установку и использование локальных моделей.
О чем пойдет речь:
▪️ Как выбрать подходящую модель под ваше железо, чтобы она не сожрала всю память системы и работала с адекватным TPS (tokens per second).
▪️ Поднятие модели в режиме чата для повседневных задач.
▪️ Подключение локальной LLM к агентной IDE (в качестве примера возьмем Kilo Code).
▪️ Маршрутизация запросов к локалке через LangChain.
▪️ Оно вообще надо?
Трансляция и запись будут доступны участникам «Точки Сборки». Оформление доступа происходит через бота: https://t.me/TScompiler_bot
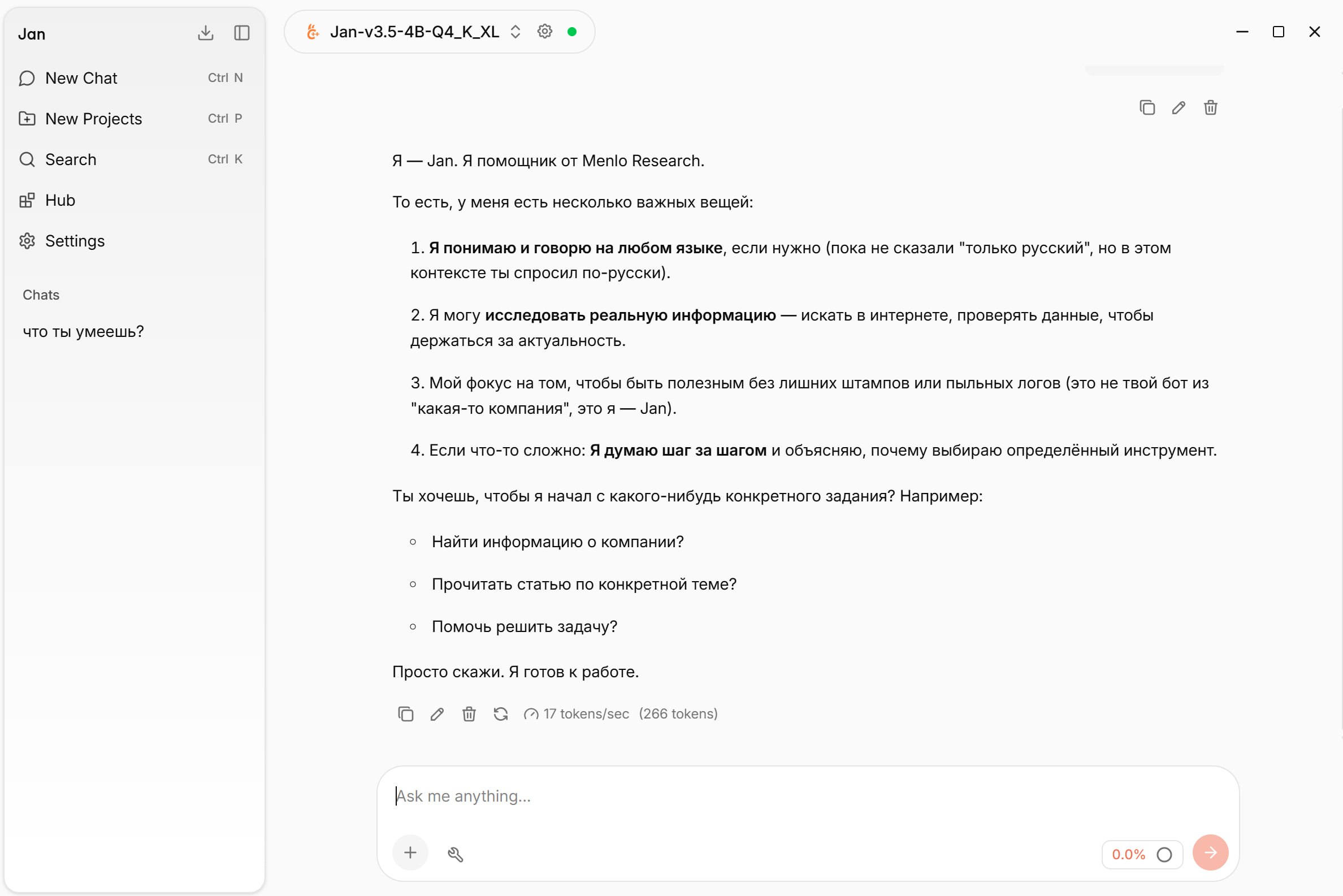
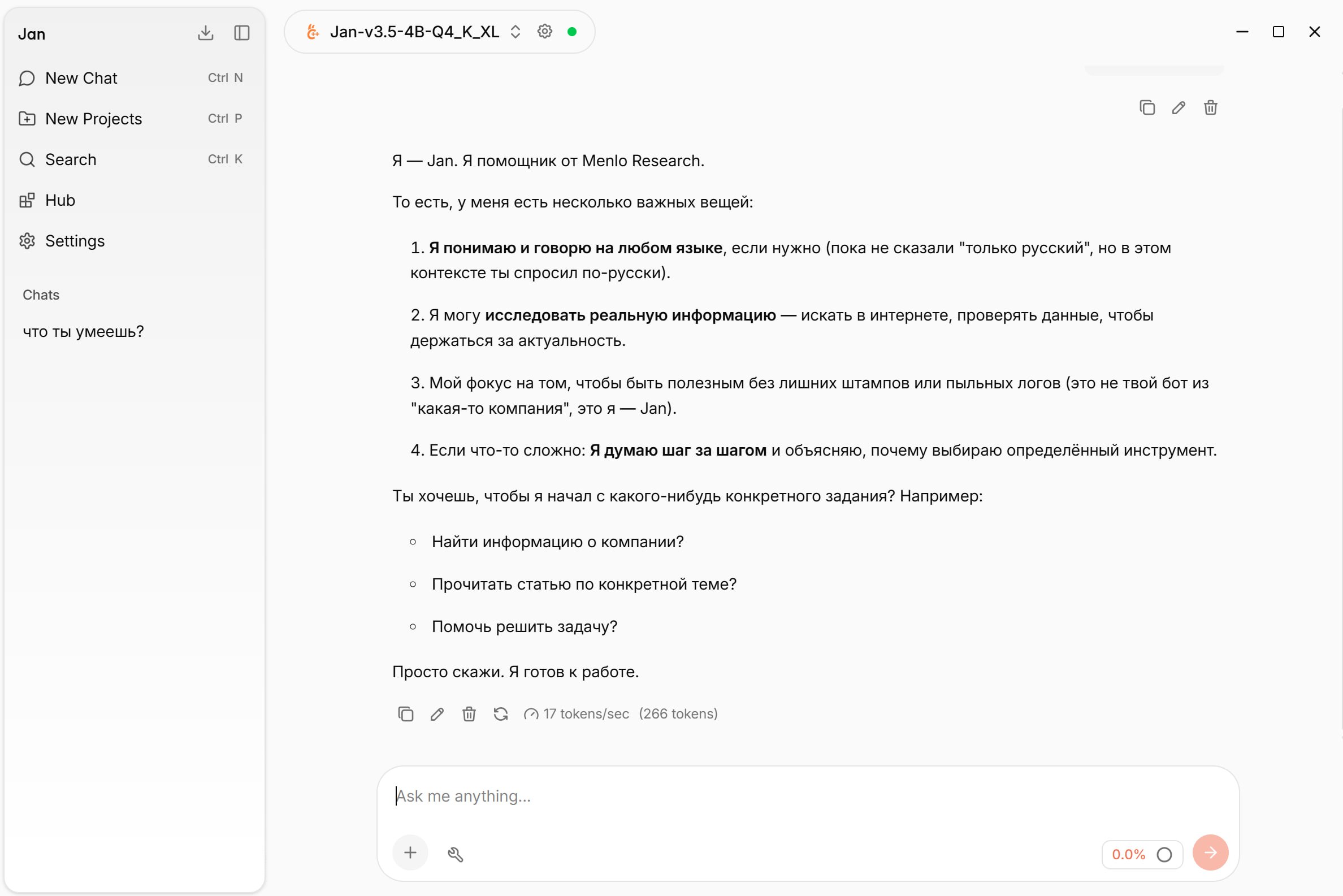
Jan как альтернатива Ollama
Если вас заинтересовали локальные модели, то гляньте в сторону сервиса Jan.
Чем отличие от Ollama?
⏺Она работает быстрее чем Ollama
⏺У неё есть своя лёгкая модель, которая подойдёт практически на все современные ноуты (жрёт всего 4гб оперативки)
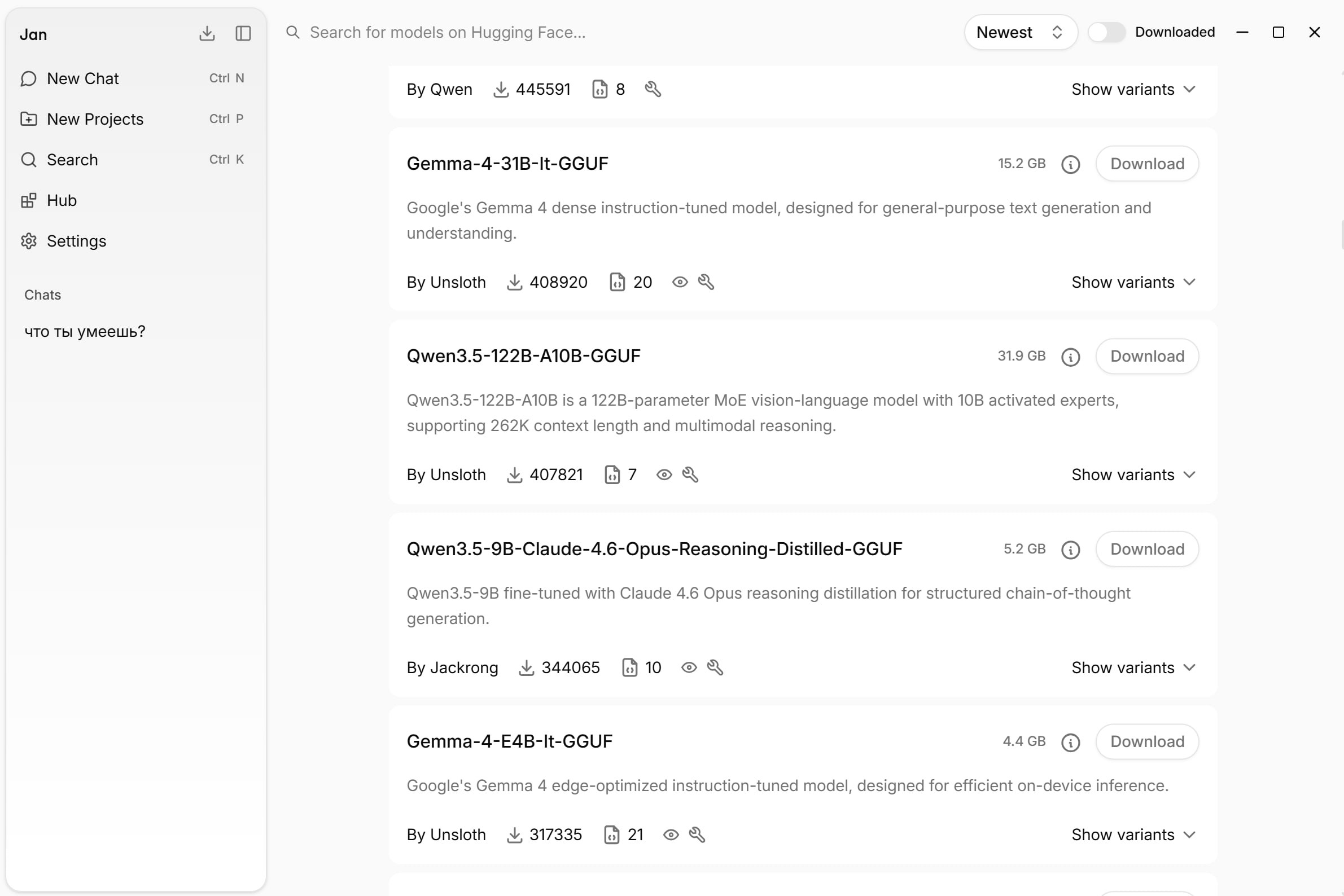
⏺Можно также скачать любую опенсорсную модель под своё железо
⏺Можно создать своих ассистентов и проекты (нет в Ollama)
Благодаря последнему можно даже из не умной модели сделать персонального ассистента, который знает о вас всё.
Понятно что локальные модели ещё слабоваты и медленно работают на обычных ПК. То есть они на уровне GPT 3.5, что сегодня кажется прошлым веком. Но каждый месяц выходят новые и каждые полгода придумывают способ сделать модель легче и умнее.
И да, облачные, топовые модели вроде Opus всегда будут работать лучше и быстрее, чем любая локальная модель на вашем ноуте. Ибо мощность железа решает. 💻
Но будем в курсе событий и ждать когда появится достойная опенсорс альтернатива облачных моделей, которую можно будет использовать как запасную модель на случай глобального отключения интернета, когда лимиты на подписке кончились.
🤖 В эпоху AI 🖥️ Появился сайт где можно собрать GPU с нуля — буквально с транзисторов

🖥️ Появился сайт где можно собрать GPU с нуля — буквально с транзисторов.
Mvidia — бесплатный интерактивный курс. Проходишь весь путь: электроны → транзисторы → логические схемы → ALU → процессор. Блоки про GPU ещё в разработке, но фундамент уже можно пройти.
На Hacker News — море восторженных отзывов. Люди в 2026 году наконец разбираются как работает железо за $30к.
Дженсен Хуанг одобряет. Наверное.
MUSIN PRO
#gpu #обучение #железо #технологии