Python-атрибуты: разбираемся, как они работают 🐍
Атрибуты — это фундамент объектной модели Python, но большинство новичков (и даже многие мидлы) используют их интуитивно, не понимая, что происходит "под капотом". В итоге — непредсказуемое поведение кода, пожирание оперативы и спагетти-API.
Давайте разбираться в нюансах 👇
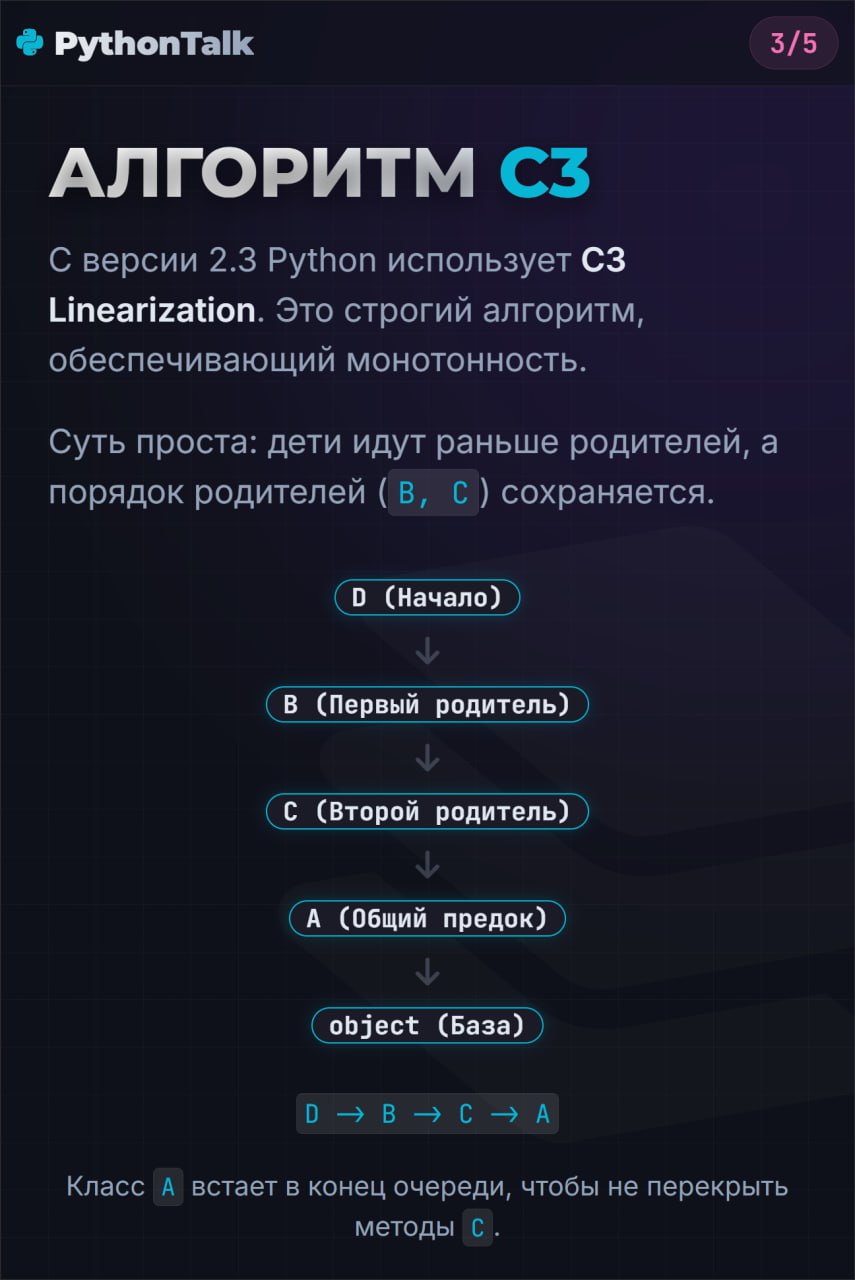
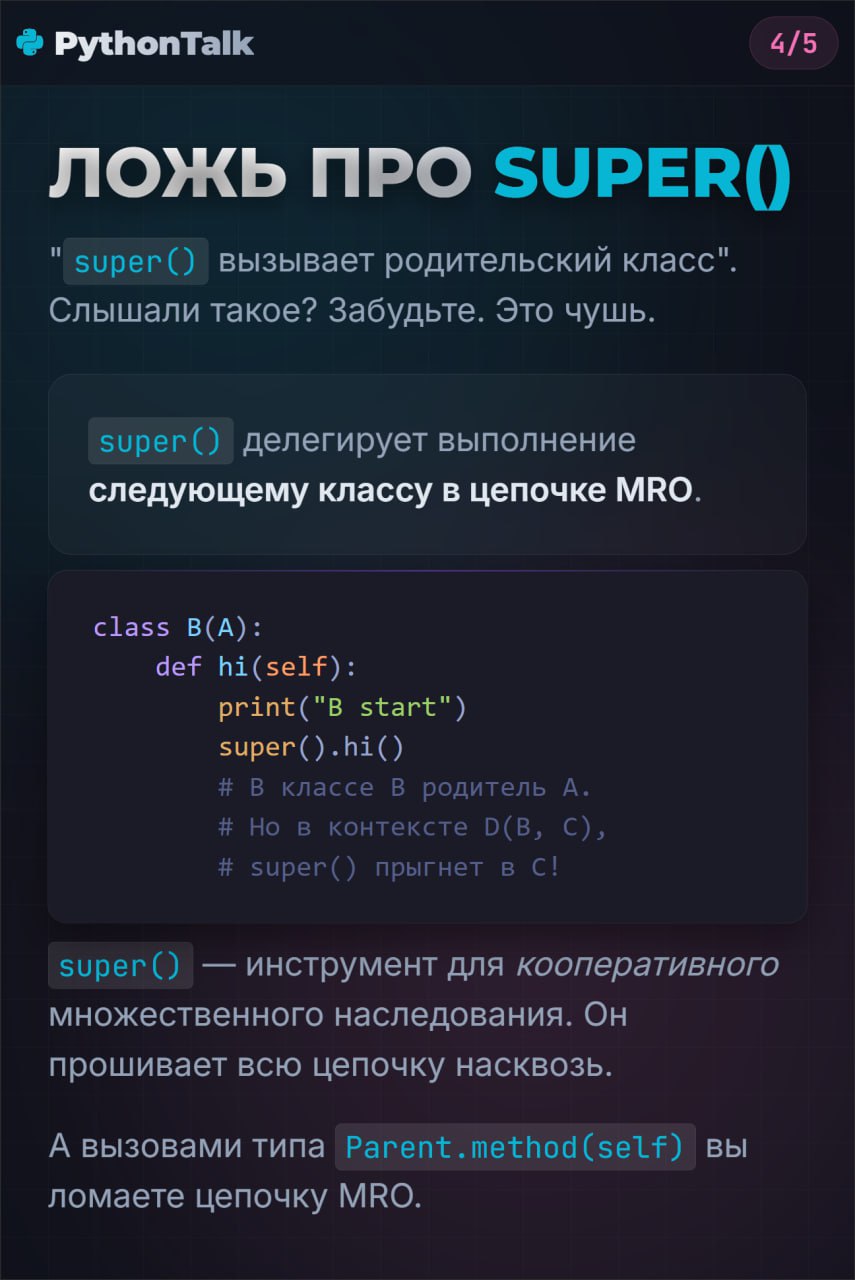
1️⃣ Порядок поиска (MRO)
Python живет по принципу: сначала объект, потом класс.
Когда вы обращаетесь к
obj.attr, интерпретатор лезет сначала в obj.__dict__. Если не нашел — идет в Class.__dict__.Если вы случайно запишете что-то в
obj.attr, вы создадите атрибут экземпляра, который скроет атрибут класса.class Hero:
weapon = "Sword"
h = Hero()
h.weapon = "Gun" # Теперь у h свое оружие, а класс по-прежнему с мечомЭто не баг, это фича, но контролируйте это. Если хотите изменить атрибут для всех — стучитесь в класс.
2️⃣
__dict__ vs __slots__По умолчанию каждый объектdictn имеет
__dict__ — хэш-таблицу (словарь), где хранятся атрибуты. Это гибко, но дорого по памяти.Если вы создаете миллионы объектов одного тиslotsьзуйте
__slots__.🔵Что это дает: Мы запdictоздание
__dict__ для экземпляра, жестко фиксируя набор атрибутов в памяти (как массив).🔵Профит: Минус 25-30% потребления памяти и чуть более быстрый доступ.
🔵Цена: Вы теряете динамическую возможность добавлять новые атрибуты на лету.
3️⃣ Иллюзия инкапсуляции
В Python нет "private" полей. Совсем.
Конструкции вида
__attribute — это не защита данных, а name mangling (искажение имен). Python просто переименовывает переменную в _ClassName__attribute, чтобы случайно не перетереть её в наследниках.Если вы пишете
__ с надеждой, что никто не долезет до ваших данных, то любой, кто умеет пользоваться dir(), увидит всё. Пишете _private (один подчерк) — значит, "не трогай, это внутренний API". Это вопрос культуры, а не компилятора.Хотите скрыть данные? Используйте один нижний подчерк
_ только как сигнал коллегам: "Не трогай это, это внутренняя кухня". 4️⃣ @property: этичный геттер
Никогда не делайте в Python Java-style геттеры (
get_value(), set_value()). Если вам нужна логика при доступе к атрибуту — используйте @property.@property позволяет превратить метод в атрибут. Вы сохраняете чистый API (доступ через точку), но под капотом можете валидировать данные, логировать доступ или вычислять значения на лету. class DataStorage:
def __init__(self, value):
self._value = value
@property
def value(self):
return self._value
@value.setter
def value(self, new_val):
if not isinstance(new_val, int):
raise ValueError("Только int, детка")
self._value = new_valТак вы сохраняете чистый интерфейс:
obj.value = 10 выглядит так же просто, как работа с обычным полем, но вы контролируете, что именно туда записывается.Какие еще "магические" места в Python вызывают у вас вопросы? Накидайте в комменты, разберем. 👇
#анатомия_питона